
介绍
在自动化或者爬虫登陆网站时经常遇到验证码模块,这也算是反爬的一种手段。这篇文章将介绍如何在selenium框架下自动识别验证码登陆。
一:安装Tesseract-ocr
Tesseract-ocr是文字识别系统,能识别英文、数字,如果需要识别汉字,则需要导入汉字语言包。
- 在Windows下安装
下载地址:Tesseract-ocr,这里可以选择版本,本机中选择4.0.0版。下载后默认安装,这里可以选择修改原安装路径,但修改后在后续进行环境变量的配置时记得更改。
安装完毕后,配置系统环境变量。在Path一项中新增Tesseract-ocr的安装路径。
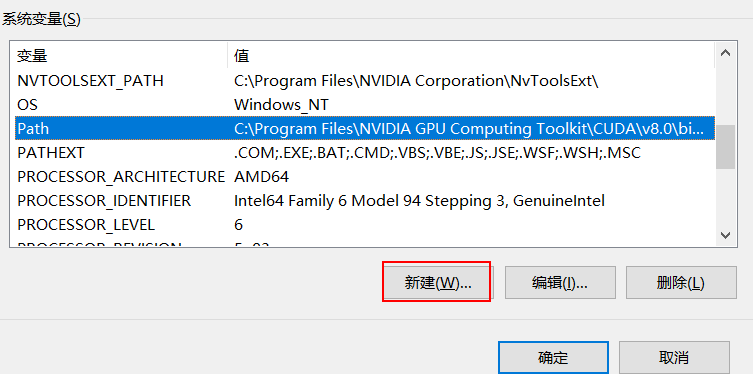
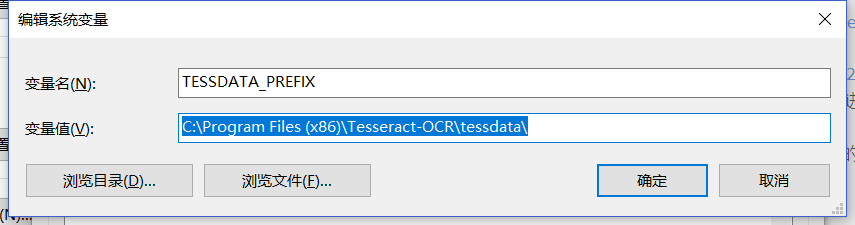
接着在系统变量中新建如下系统变量,告诉Tesseract-ocr数据集的位置。
然后验证是否安装成功。

- 在Linux下安装
直接执行:apt install tesseract-ocr。
二:python脚本
1 | |
代码说明:selenium自带有截图功能,如果是选择非PhantomJS作为浏览器的话,当使用browser.save_screenshot("temp.png")时截的只是当前浏览器窗口显示的图片而不是整个网页,但使用PhantomJS时,截取的是整个网页。
selenium也可以选择区域或网页元素进行截图,不过需要PIL辅助,先从网页中获取该元素的位置,然后使用PIL Image里的crop截取。这里需要注意,如果使用例如Chrome等浏览器而非PhantomJS的话,会因为浏览器弹出的位置不同,导致无法准确的截到该元素的位置,需要自己反复调节,但使用PhantomJS时不会有这个问题。
可以注意到,我这里是使用系统调用的方法进行识别,但有另一种方法是安装pyocr。直接执行pip install pyocr即可。由于作者不熟悉,加之有急需,故不再演示,只提出方法。